検索エンジンが数あるWebサイトの中から、情報を収集する際に欠かせない存在であるクローラー。
SEO対策を担当されている方の中には「SEO対策においてはクローラビリティが大事!」という話を聞いたことのある方も少なくないでしょう。
しかし実際、クローラーの存在は何となく把握しているものの、人に説明できるレベルで詳しく理解できていない方も多いですよね。
結論から言うと、クローラーは検索エンジンにおいて情報取得・収集の役割を担っている、SEO対策を学ぶなら理解しておかねばならない機能の1つです。
この記事では、クローラーとは何か、検索エンジンにおける役割、クローラビリティ向上のコツ、などについて具体的に解説します。
読み終えれば、あなたもクローラーについて具体的に理解し、SEO対策に活用できるようになるはずなので、ぜひ参考にしてみてくださいね。
クローラーとは「ネットの情報を巡回して取得するプログラム」のこと
クローラーとは、ネット上に存在しているWebサイトを巡回して情報を取得・変換し、検索データベースを作成するプログラムのこと。
英単語の「Crowl(這う)」に由来しており、インターネットの情報を這うようにして取得していることからクローラー(Crowler)と呼ばれているんだとか。
現在ほとんどの検索エンジンがロボット型検索エンジンを利用しており、自動でWebサイトの情報収集・取得して、データベースに登録しています。
そのためクローラーは別名「スパイダー」「ロボット」「ボット」などとも呼ばれており、いわば自動でインターネット情報の海を巡回する監視係なのです。
クローラーは既に登録されているWebサイト内でリンクを発見すると、リンク先へ遷移して巡回を続けます。
ページに辿り着いたクローラーはパーシング(解析)を行い、ページ内の情報を取得し、検索アルゴリズムが読み取れるように変換。
変換したものをデータベースに登録して、一旦仕事完了です。
ただ、もしもパーシングの最中に、何か別のリンクを発見したら、リンク先に飛んで同じ作業を行うように設定されています。
クローラーは永遠とこの作業繰り返し続けているおかげで、Webページが新しく作成されたり、情報が更新されたりすると、検索結果に反映されるのです。
検索エンジンとクローラーの関係
一般的に検索エンジンは、3つの作業を行っています。
- クローリング(情報の検出)
- インデックス(整理)
- 検索アルゴリズムによるランキング(順位付け)
クローラーはこの作業の内、最初の段階である「情報の検出」を行っており、情報を取得してインデックスするまでが仕事です。
検索エンジンについて詳しく知りたい方は、下記の記事で詳しく解説しているため、ぜひ参考にしてみてください。
クローラーの種類
検索エンジンごとにクローラーは独自のものが使われており、各検索エンジンごとに様々な名前がつけられています。
- Googlebot(Google)
- Bingbot(bing)
- Yahooo Slurp(Yahoo!日本以外)
- Baiduspider(Baidu)
- Yetibot(Naver)
近年は検索技術自体の発展にともなって、画像検索専門のクローラーやモバイル検索専用クローラーなど様々なものが存在します。
クローラーが取得する対象のファイル
- HTML/CSSファイル
- テキストファイル
- JavaScriptファイル
- PHPファイル
- 画像
- Flash
クローラーは、Webサイトを構成する要素やタグなどをきちんと取得するように設計されています。
Webサイトを制作する際、ブログを執筆する際などは、きちんとクローラーが読み込めるような形で書くように心がけましょう。
クロールバジェットを考慮する必要はない
Googleが設けているクロールの上限数のことを「クロールバジェット」と呼んでいます。
Webサイト内においてクローラーがクロールできる数には限界があるため、環境によってはURLがクロールされなくなってしまう現象が生じます。
この上限値のことをクロールバジェット(Crawl budge:クロール予算)という名称を付けて呼んでいるのです。
ただクロールバジェットを考慮すべきは、あくまでも無限にURLが生成されてしまうようなサイトだけ。
通常のコンテンツ数1000記事以下のサイトにおいては、気にする必要等は一切ないといっても過言ではないので、概念として覚えておくに留めておきましょう。
クローラーが自分のサイトに来たか確認する方法
クローラーが自分のサイトに来たか確認する方法は主に3つ。
- 「site:」を利用して検索する
- 「クロールの統計情報」を確認する(Google Search Console)
- 「URL検査」を利用する(Google Search Console)
「site:」を利用して検索する
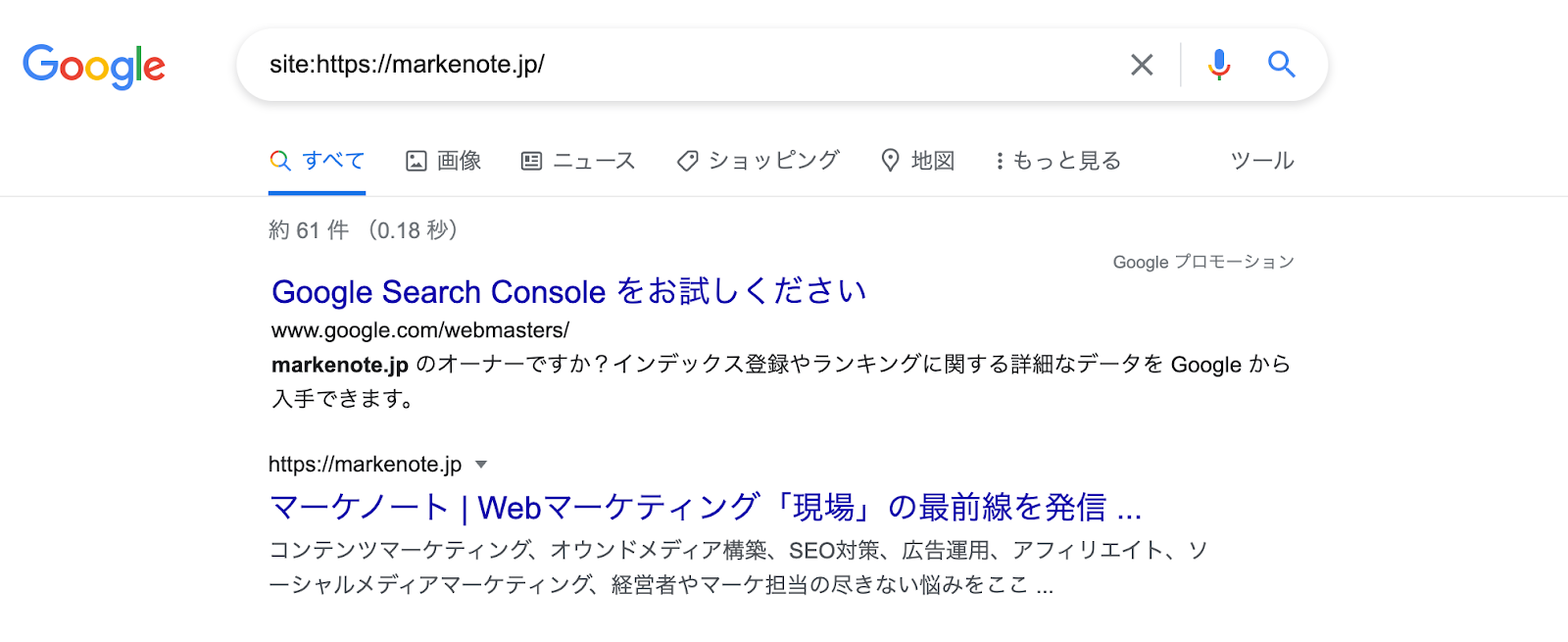
クローラーが巡回しているか確認する1番簡単な方法は、検索窓に「site:」をつけて調査する方法でしょう。
Googleの検索窓に、
- site:(URL)
と打ち込んでみてください。
例として弊社のメディアを挙げるなら、
- site:https://markenote.jp/
というURLになります。
クローラーがWebサイトに巡回しているのであれば、下記のように検索結果にきちんと反映されます。
また同様に、ドメインだけでなく、新しい記事を更新した場合にも、チェック可能なので、ぜひ行ってみてください。
「クロールの統計情報」を確認する(Google Search Console)
「自社のページがどのくらいクロールされたか」をチェックするなら、Google Search Consoleにおいて「クロールの統計情報」を確認する方法がおすすめです。
まずGoogle Search Consoleにおいて、左側のメニューバー「設定」から「クロールの統計情報」>「レポートを開く」を選択。
そこでクロール統計情報が表示されるので、クローラーが訪れたページ数を日付別で確認することができます。
しかしこの方法だと、どのページにクローラーが回っているのか、ページ毎に確認することはできません。
あくまでもサイト全体として、どのくらいクローラーが巡回しているのかを把握するための手段として考えておくと良いでしょう。
「URL検査」を利用する(Google Search Console)
Webページがクロールされているか、最も確実に確認する方法は、Google Search Consoleの「URL検査」を利用する方法です。
Google Search Consoleで左側メニューにある「URL検査」を選択します。
すると1番上部の検索窓が反応し、

上キャプチャのように出力されるので、この部分に調べたい記事のURLを入力します。
URLを入力すると、きちんとインデックス登録されていれば「URLはGoogleに登録されています」と表示されます。

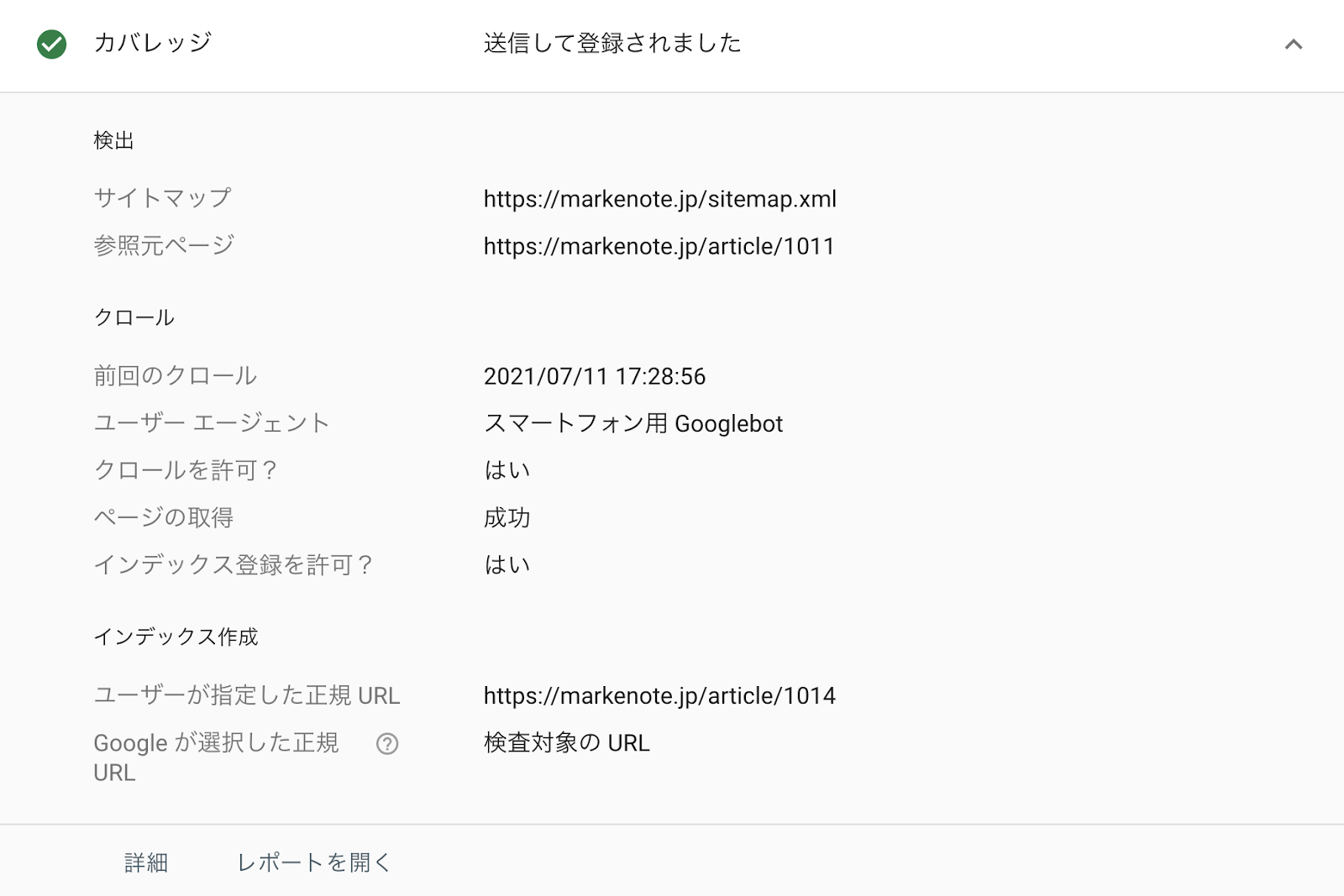
また画面中部の「カバレッジ」を選択すると、
- 前回クロールされた日時
- クロールの結果
などを算出してくれるため、非常に詳細まで詳しく知ることが可能です。
URLがきちんとクロールされているか確認する上では欠かせないツールなので、絶対に覚えておくようにしましょう。
SEO対策においては「クローラビリティ」が重要
SEO対策においては、しばしば「クローラビリティが大事」と言われていますよね。
クローラビリティとは、サイト内におけるクローラーの「巡回しやすさ」のこと。
まず適切にサイトを評価してもらうためには、クローラーにサイトを隅々までクロールしてもらわなければなりません。
クローラビリティが低いサイトの場合、上手にページを読み込んでもらえなかったり、読み込みにくさがページとしての評価を妨げたりすることも。
しっかりクローラーにWebページの情報を読み取ってもらうためにも、クローラビリティの高いサイトづくりを目指しましょう。
Webサイトでクローラビリティを向上させる7つの方法
具体的にWebサイトにおいて、クローラビリティを向上させる方法を7つ挙げました。
- Google Search Consoleでサイトマップを送信する
- HTMLを基本に忠実に書く
- 関連記事を内部リンクとして貼り付ける
- アンカーテキストを内容が分かるように記述する
- サイトの構造を3段階までに設定する
- 被リンクを獲得する
- URLを正規化する
ページをきちんと読み込んでもらうためにも、クローラビリティは非常に重要なので、ぜひ7つの方法を意識してみてくださいね。
Google Search Consoleでサイトマップを送信する
サイトマップとは、サイト全体の構造・動画や画像・テキストコンテンツを検索エンジンに理解してもらうための地図のようなもの。
そもそもクローラーが全てのページをひとつひとつチェックするには時間がかかります。
その点、サイトマップならサイト構造をひとつのファイルにまとめているので、クローラーが理解しやすいのです。
全くリンクされていないページなども、クローラーにきちんと把握してもらえるのもサイトマップの魅力。
Search Consoleの左側メニューにある「サイトマップ」から、サイトマップURLを送信すればいいだけなので、まだ送っていない方は、送ってみてくださいね。
HTMLを基本に忠実に書く
HTMLタグを基本に忠実に、構造を意識して書くというのも、ユーザービリティを向上させる上では重要です。
クローラーは自動で動いているロボットであり、Webサイトはクローラーが理解しやすい言語で作られています。
例えば、タグが間違っていたり、適切な構造でHTMLを書いていなかったりすると、クローラーにとって読み込みにくくなってしまうことも。
結果的に、クローラビリティが低下し、検索順位にまで影響が出てしまうこともあります。
クローラビリティを高めるためにも、基本に忠実にHTML/CSSを書くように心がけましょう。
関連記事を内部リンクとして貼り付ける
Webサイト内部の関連記事を内部リンクとして貼っておくというのも、クローラビリティを向上させる上で非常に重要です。
先述したように、クローラーはサイトの内部に設置されたリンクを辿って、Webページを発見します。
内部リンクを設置しておけば、リンクを辿ってクローラーが隅から隅まで巡回できるので、クローラビリティの向上につながります。
具体的には、記事内に内部リンクを貼り付けたり、カテゴリー・アーカイブページなどを作ってリンクを一覧表示するのも有効。
関連記事をリンクとしてきちんと貼り付けておくように心がけましょう。
アンカーテキストを内容が分かるように記述する
アンカーテキストとは、リンクが貼られている部分のテキストのことで、リンク先がどのようなページなのかを伝える役割があります。
クローラーはリンクを辿ってサイトを探すので、アンカーテキストの内容からリンク先の情報を読み取ることもあるのです。
もしもアンカーテキストが「こちらの記事」「この」などのテキストである場合、クローラーにとって関連性を読み取りにくく、回遊率が大きく低下してしまいます。
クローラビリティを向上させるためにも、アンカーテキストは内容が分かるように記述しましょう。
サイトの構造をなるべく簡易化する
サイトにおいてカテゴリごとにページを分類することは、ユーザーにとってサイト見やすさを左右する重要な要素です。
かといって、カテゴリ数を増やしすぎたり、階層を細かく分ければ分けるほど良いということでもありません。
深層まで下層ディレクトリをつくってしまうと、ユーザーにとってストレスになる可能性が高いですし、クローラーもたどり着きにくくなってしまいます。
基本的にはサイトは「トップページから2クリック以内にすべてのページにたどり着ける」ことが理想であるため、なるべく簡易化しておくことをおすすめします。
被リンクを獲得する
被リンクを多数獲得することは、外部サイトからクローラーが巡回する機会を増やすことにつながります。
人気の高いページになると、被リンクが増えて、そのページに対するクロールの必要性が大いに上がります。
Googleは人気の高いURLほど、インデックスでの情報の新しさが保たれるように重要視するため、頻繁にクロールされるようになる傾向にあるのです。
また良質な被リンクを獲得することは、単純にSEO的にも良い評価を及ぼすので、一石二鳥なのです。
URLを正しく設定する
Googleでは公式に「過度に複雑なURLはクロールの際に問題を引き起こす可能性がある」として明示しています。
特に複数のパラメータを含む URL など、過度に複雑な URL は、サイト上の同じまたは同様のコンテンツを表す多数の URL を不必要に作成し、クロールの際に問題が生じることがあります。その結果、Googlebot が必要以上に帯域幅を消耗してしまい、サイトのコンテンツをすべてインデックスに登録しきれない状態を招く可能性があります。
引用元:Google検索セントラル
つまり出来る限り利用する文字列を減らして、シンプルなURLに仕上げることが、クローラビリティを改善する上で大きなポイントになるのです。
例えば、SEO対策に関する記事を書いたのであれば、「https://〇〇/seo」などと簡単に設定することで、クローラーの負担を和らげることが可能に。
なるべくシンプルに保つことが推奨されている以上は、きちんとシンプルにURLを設定することを心がけておきましょう。
まとめ|クローラーが巡回しやすいサイトづくりをしよう!
クローラーに巡回してもらいやすいサイトを作ることは、SEO的な評価にも良い影響を与えることができます。
きちんと巡回してもらえるサイトなら、新しい情報を更新した時にもクローラーに見つけてもらいやすくなるため評価されます。
Web担当者の方は、本記事で紹介した7つのことを意識して、クローラーに巡回してもらいやすいサイトを制作するように心がけましょう。